Logogens were one of the first elements of cognitive theory to be postulated. They were created as a result of work I did in the 1950s on the effectiveness of Reading Improvement Courses. This was done on behalf of the British Post Office, who sponsored my PhD in the Psychology Department of Reading University under the supervision of Professor Maggie Vernon. I looked at a couple of courses run for Post Office civil servants. The courses comprised 12 sessions of a couple of hours each, aimed at training eye movements into larger saccades and to inhibit regressions (backwards jumps). These were known to be the characteristics of good readers, and the behaviourism of the day could see no problem with the idea that forcing the eyes into a good pattern would improve reading speed at no loss to comprehension! I designed a measure of reading efficiency, involving speed and comprehension, and tested the students before and after the course. Well, the courses that I monitored seemed to work very well, but the strange thing was that some people who had only been able to attend one or two of the twelve sessions managed to improve their reading efficiency 100-200%. Since I did not believe that anything could have been trained in that time, in the normal sense of the word, I deduced that these high flyers had simply started to use some knowledge they already possessed but had not previously been using. Given the intellectual climate at the time, the obvious candidate was knowledge of the statistical properties of the language.
George Miller had recently demonstrated that it was easier to hear words in sentences than the same words in random order. This was somewhat mysterious. How could such a variable affect perception? Surely perception was simply our response to the properties of the stimulus? It was also believed that word frequency affected word perception, and experiments were designed as if word frequency [which could be looked up in a book] was a property of the stimulus words, and which functioned in much the same way as stimulus contrast would function. So the logic ran: if you decrease the contrast, then a word will be more difficult to read; if you increase the frequency of a word it will be easier to read! Anyway, no experiments had been done on the effects of context while reading words, and that is what I decided to do for the rest of my thesis.
The first experiment looked at the effect of context on word perception. To prepare the stimuli, I had a set of sentences like “Coming in, he took off his ____”, and I got subjects to complete these sentences. I could then select high and low probability words in the context, and also find contexts that predicted a particular word to a greater or lesser degree. The subject would see a context sentence and then the target word was exposed for a brief period. The length of the exposure was increased until the subject reported the word correctly. The data showed that the probability of a word in a context predicted its ease of reading as measured by the length of time the word needed to be exposed for the subjects to get it right. However, it was not possible to think in terms of these probabilities being a property of the words themselves, since these probabilities had themselves been produced by other subjects. So, I had two pieces of behaviour that were related to each other, word generation in sentence contexts and word recognition in the same sentence contexts. They were related to each other by virtue of the subjects’ knowledge of language, and the result was the same in the two cases – the production of a word such as “coat”. I assumed that the same element would be used whenever a response was made of a particular word irrespective of the cause of the response. I originally called these elements “units”; the term “logogen” was suggested later by the physiologist Hallowell Davies, on the grounds that “unit” sounded too physiological when it was clear that I was proposing a psychological construct. At the same time, Anne Treisman, doing her PhD at Oxford on dichotic listening, was developing related ideas with what she called “dictionary units”.
In any event, I drew a diagram like figure 1,
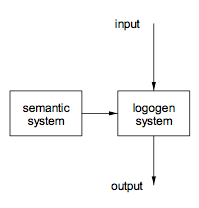
FIGURE 1
The first version of the logogen model which postulated two separate functional systems, the semantic system and the logogen system. Inputs relevant to words would be input to the logogen system and would accumulate in the relevant word generating units or logogens. When more than a threshold amount of information had accumulated in any unit, it would fire and the relevant word would become available as an output or response. Context was represented in the semantic system that would pass relevant information to the logogen system on a moment-to-moment basis. Thus, if the context included the verb “take off”, there would be a semantic representation of “clothing” which would be sent to the logogen system. In this way the logogens related to the responses “coat” and “hat” would receive activation. In the absence of any stimulus, the logogens would be driven solely by the context. When there was both stimulus and context, the two sources of information would interact. If there were relevant contextual information from the context, less stimulus information would be required for the appropriate logogen to fire, and the word to be available as a response. My initial assumption was that all inputs – visual, auditory, pictorial – would have their effects in the same place.
This work was completed in 1959. I did other work on the effects of context in reading and completed my PhD in 1961. None of this work got into print until 1964 – partly a result of the more casual attitudes to publishing in those days and partly the much greater lag times with the journals.
The next question was to do with the nature of the interaction between sensory and contextual information. The simplest way of thinking about it was in terms of adding information. Since the two sources of information were orthogonal, this was straightforward. How would this work in practice? Well, suppose that there is a certain amount of relevant visual information produced by a visual input system. This would be in the form of constituent letters, letter parts or information about the word as a whole such as length or shape. Each such piece of information would get sent to all the logogens for which it was applicable. This is standard in connectionist models nowadays. Any logogen that receives such an input would have an increase in activation. If there was more than a threshold amount of information the logogen would fire, and the corresponding word would be sent to an output buffer. I inserted an output buffer because it was clear that we had an option as to whether to say the word. Since we could wait as long as we wanted before responding, there had to be somewhere to store that information. Since we could say that response to ourselves – rehearse it, in other words – there had to be a way of recycling the information. The 1969 version of the model is shown in figure 2.

FIGURE 2
I started thinking about the mathematical implications of the model, using Signal Detection Theory. [1] This proved too difficult for me but I could use a simplification based on Luce’s Choice Axiom Theory.[2] After quite a bit of work I derived the equation:
logit(psc) = logit(ps) + logit(pc) + constant
Where logit(p) is log(p/1-p), and ps is the probability of getting a stimulus word correct with a specific length of exposure, with stimulus information alone pc is the probability of getting it right with context alone – that is guessing – and psc is the probability of getting the word of that exposure correct with added context. I then applied this formula to data from a paper by Tulving, Mandler and Baumal (1964) who had looked at the effects of sentence context on word perception and had more extensive data than I had collected. In particular, they had looked at the effects of different levels of context at each of a number of exposure durations. They had plotted their data as shown in figure 3 below.
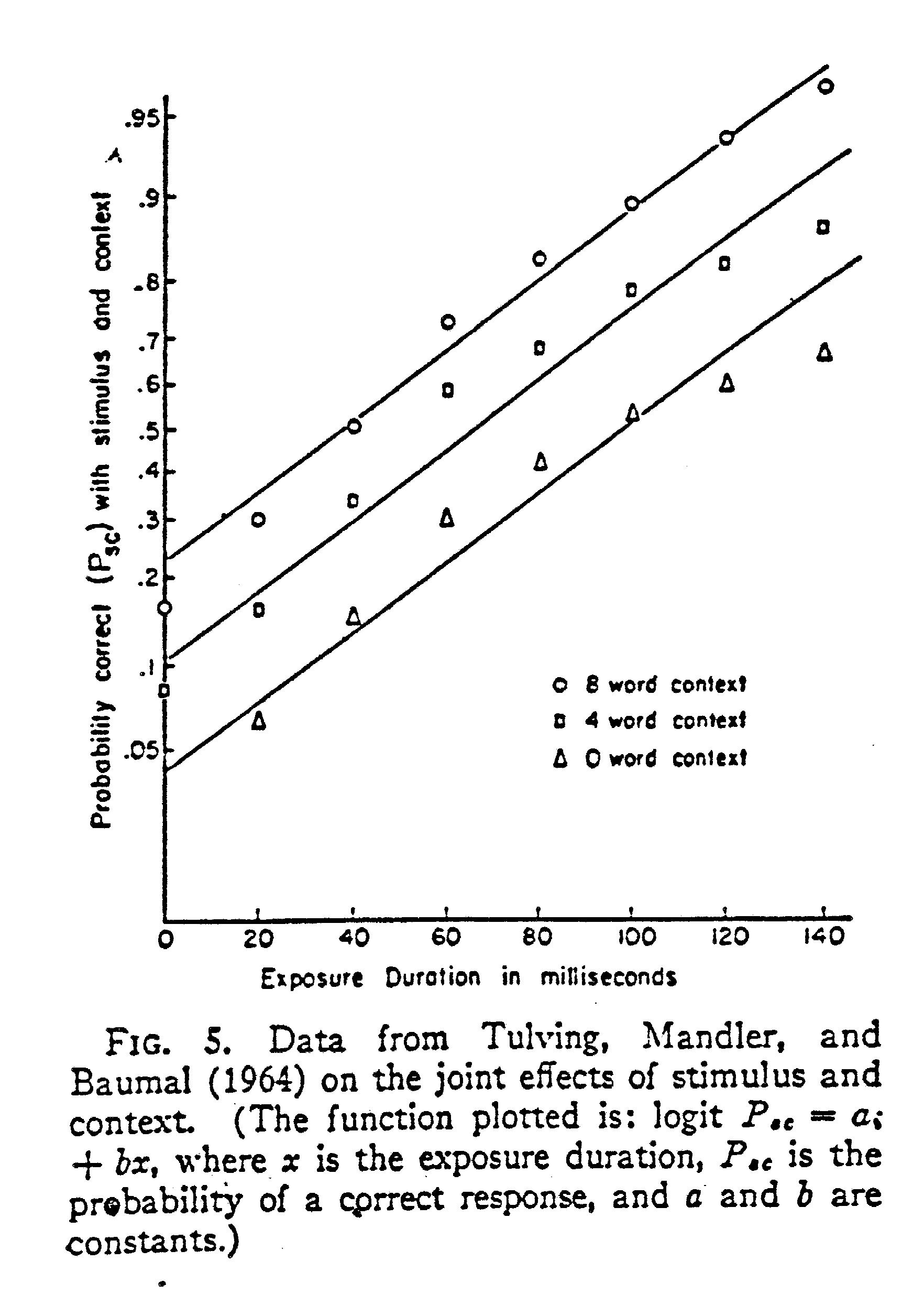
FIGURE 3
When I re-plotted it according to the equation I found the straight lines shown in figure 4.

FIGURE 4
Remember that the equation was derived from my 1969 model. The one point that does not fit is for the highest levels of context and exposure where the number of options left from the context are so few that subjects can use different methods for working out what the stimulus is. Amusingly, when it reproduced this figure, the journal omitted the really deviant point, so the fit looked better than it was. This paper took a little while to get known but has been cited frequently ever since.
The model is very simple and very powerful – but it is wrong! Wrong not in the nature of the interaction tested by the equations, but in the connectivity among the elements. I had a period of time when I felt that there was a problem but did not know why. I searched the literature again and found a study by Winnick and Daniel (1970). I had read this study when it came out but had not recognised its importance. These authors had presented their subjects with words, objects and definitions of words. In all cases the subjects responded with a single word. Later on, all the words, plus control words, were presented for recognition in a tachistoscope. The prediction from the current logogen theory was clear. In all cases there should be facilitation of recognition compared with the control words because the same logogen would be active whenever a particular word was made available as a response for whatever reason. This activation should lead to facilitation in a subsequent visual recognition study. Winnick and Daniel found facilitation of word recognition for the items previously presented as words. But, alas for the logogen theory, they showed clearly that there was no facilitation following the naming of a picture or filling a definition.
Perhaps their data was no good! So the next thing I did, with a bright undergraduate called Bob Clarke, was to repeat their experiment. We got the same result as them: word recognition was facilitated following prior presentation of the word but not by naming a picture or filling a definition. Did it have anything to do with repeating the same stimulus pattern? To test that hypothesis, we compared pre-training using typewritten and handwritten words versus getting the subjects to produce the same words in response to definitions. The handwritten words were scrawled but readable. The visual recognition was done with typewritten words. Typewritten and handwritten words both produced facilitation. The definitions did not, although the response was the same [the spoken word]. So the crucial thing for facilitation was not stimulus identity. The minimum modification to the model to account for the data is shown in figure 3, [figure 3 needs caption] with a direct connection from the context [cognitive] system to the output system, through which the definitions would be filled. Of course, this would require that the context system could produce and output the phonological forms of the words in question. This would involve duplicating the phonological information in the logogen system – a rather clumsy step.
According to this model, it would not make any difference what the response was since the origin of the facilitation effect was the logogen system and not the output buffer, which controlled the responses. The stimulus would be crucial. So we got subjects either to repeat the stimulus words or produce their opposites. The words were chosen so that producing opposites was very easy, such as “hot”, “wide”, “queen” and “uncle”. We also varied the nature of the stimulus, using either visual or auditory presentation. Again, the testing was done visually. There was a significant difference between the visual training and both the auditory training and the controls. The nature of the response made no difference whatever. The only way to handle this is to separate the input systems according to modality. The resulting model is shown in figure 5.
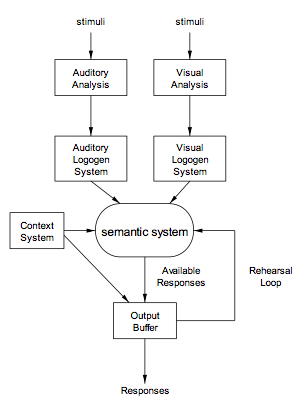
FIGURE 5
The next experiment looked at the equivalent phenomena using auditory word recognition. The task involved listening to spoken words played in noise. The level of noise was such that subjects correctly reported less than half the words correctly. Pre-training involved listening to or reading words and classifying them as animate or inanimate. The spoken training words were either in the same or a different voice [male vs female] as the target words. In this experiment, Anita Jackson and I showed that there was a small transfer from visual experience to auditory word recognition, but that the voice in which the words were spoken had no effect. The visual-auditory transfer we accounted for in other ways. Ellis and Gipson [ref] with tighter controls found no cross modal transfer at all. The conclusion is that the effects are symmetrical so far as modality is concerned.
Note that the logogen systems are defined for the moment in terms of the visual duration facilitation effect. Questions about the nature of the representation in the logogen systems remain to be asked. One experiment that addressed the issue was run by an undergraduate, Graham Murrell. We looked at the facilitation from morphologically related words as well as visually similar words. So with a target word basic, the prime word was basis, which is morphologically related, or basin, an unrelated word that is visually similar. We found that the visually related words gave no significant advantage over the control condition in which there was no relevant word in the pre-training. The morphologically related words were significantly better than either, though not as good as identity priming. We concluded that logogens represent morphemes.
The final experiment, with another undergraduate, Clive Warren, explored picture perception in a similar way. Why? We used pairs of pictures of objects like those in figure 6 below.
FIGURE 6
The experimental task involved trying to name the pictures when they were presented for a brief period. The priming task, carried out 10-40 minutes earlier, involved naming either the same picture or the related one or reading the printed name. We found that reading the name of an object had no effect at all on the subsequent recognition of the picture but the different picture, with the same name, although having less effect than the identical one, was superior to the word or the control condition. The facilitation effects have to be in the part of the system devoted to processing pictures, and we concluded that there were two systems, one employed in picture analysis and the other in picture categorisation. Note that if the same experiment were carried out with an interval of a few seconds between prime and target, you will find facilitation (Durso and Johnson, 1979). This is because the relevant word will be in Short Term Memory, and the subject will soon develop a strategy of using all available information in performing the task. Thus the system which recognises pictures behaves in the same way as the two word systems.
The importance of this work is that it has been the starting point for a vast amount of work in the area of language, thinking about normal processing or situations such as dyslexia or effects of traumatic brain damage. The theoretical technique has become so much a part of the fabric of cognitive theory that similar models have emerged without acknowledging any debt to the original.
